
小编:4月24日新闻,技术媒体Marktechpost昨天(4月23日)发表了一篇博客文章,报告说Nvidia对图像和图像做出了回应
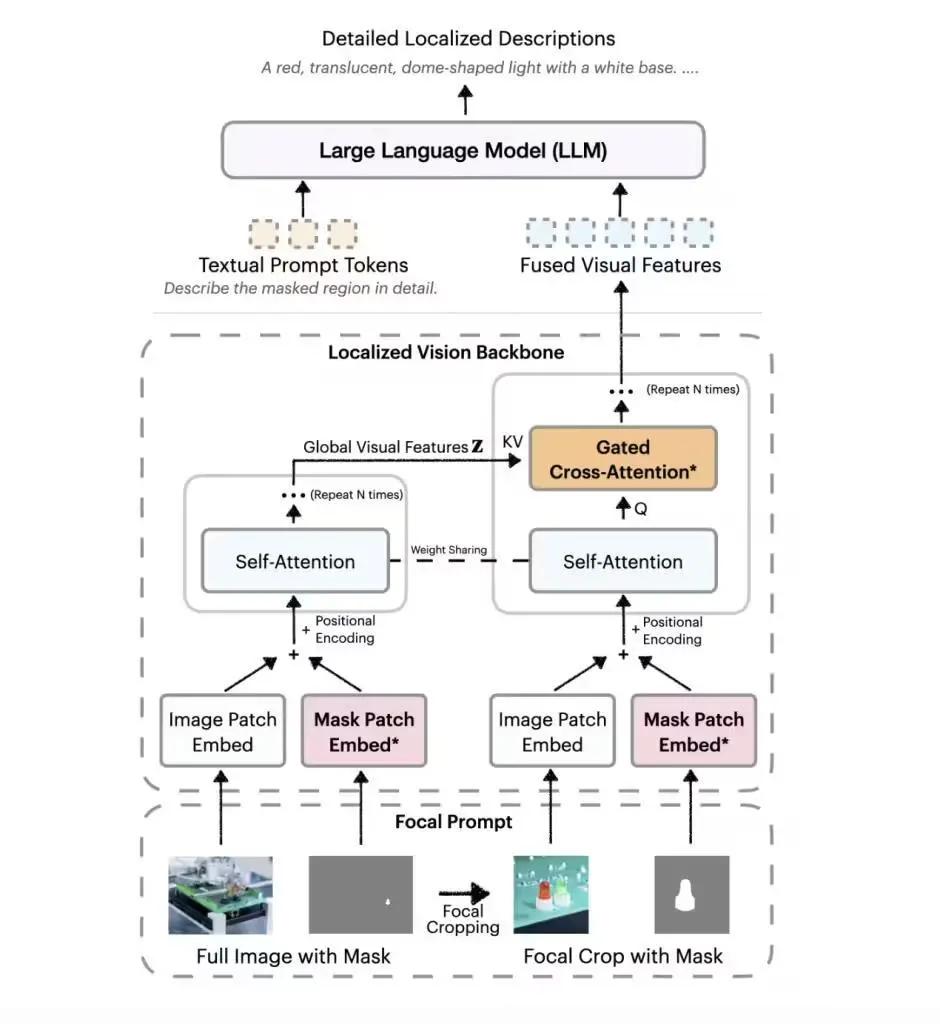 4月24日新闻,技术媒体MarktechPost昨天(4月23日)发布了一篇博客文章,报道NVIDIA最近启动了Any3B(DAM-3B)AI模型的描述,以应对图像和视频中特定位置的详细说明的问题。视觉语言(VLMS)模型在开发一般图像描述方面表现良好,但是它们通常无法详细描述特定领域,尤其是在需要动态时间要考虑的视频中,这更加困难。 NVIDIA描述了面对此问题的Any3b(DAM-3B),并支持用户按点,绑定框,涂鸦或口罩指定目标区域,以生成准确且适当的文本适当文本。 DAM-3B和DAM-3B-VIDEO适用于静态图像和动态视频,并且该模型在拥抱面平台上发布。独特的建筑和良好DAM-3B设计的主要创新是“焦点技巧”和“本地视觉骨干网络”。焦点提示技术结合了ENT以高分辨率裁剪目标区域,以确保在维持整体背景的同时不会滚动。视觉脊柱的本地网络使用封闭式的交叉和注意机制来整合全局和本地特征,然后将它们传递到大型语言模型中以生成描述。 DAM-3B-VIDEO通过通过框架编码区域掩码并包含时间信息,进一步扩展了视频字段,即使在遮挡或运动前也可以形成准确的描述。 thedata和评论是两个脚步的方法。为了解决缺乏培训数据的问题,NVIDIA使用数据集和非生成网络图像制定了DLC-SDP的半柔软效率 - 柔软的苏珀斯省效力数据数据,以产生包含150万本本地描述的样品的训练语料库。通过自我训练程序优化描述质量,以确保输出文本的高精度,团队还启动了DLC基础评论基准测试,以通过准确性级别来衡量描述的质量,而不是严格比较文本参考。 DAM-3B领导7个基准测试,包括LVIS和FLICKR30K实体,平均准确度为67.3%,超过了GPT-4O和Videorefer等模型。不仅仅是FillingDam-3B是本地描述领域的技术差距,而且了解上下文和高质量数据技术的体系结构还为没有障碍,机器人和视频内容评估的工具领域开辟了新的可能性。 【来源:这在家】
4月24日新闻,技术媒体MarktechPost昨天(4月23日)发布了一篇博客文章,报道NVIDIA最近启动了Any3B(DAM-3B)AI模型的描述,以应对图像和视频中特定位置的详细说明的问题。视觉语言(VLMS)模型在开发一般图像描述方面表现良好,但是它们通常无法详细描述特定领域,尤其是在需要动态时间要考虑的视频中,这更加困难。 NVIDIA描述了面对此问题的Any3b(DAM-3B),并支持用户按点,绑定框,涂鸦或口罩指定目标区域,以生成准确且适当的文本适当文本。 DAM-3B和DAM-3B-VIDEO适用于静态图像和动态视频,并且该模型在拥抱面平台上发布。独特的建筑和良好DAM-3B设计的主要创新是“焦点技巧”和“本地视觉骨干网络”。焦点提示技术结合了ENT以高分辨率裁剪目标区域,以确保在维持整体背景的同时不会滚动。视觉脊柱的本地网络使用封闭式的交叉和注意机制来整合全局和本地特征,然后将它们传递到大型语言模型中以生成描述。 DAM-3B-VIDEO通过通过框架编码区域掩码并包含时间信息,进一步扩展了视频字段,即使在遮挡或运动前也可以形成准确的描述。 thedata和评论是两个脚步的方法。为了解决缺乏培训数据的问题,NVIDIA使用数据集和非生成网络图像制定了DLC-SDP的半柔软效率 - 柔软的苏珀斯省效力数据数据,以产生包含150万本本地描述的样品的训练语料库。通过自我训练程序优化描述质量,以确保输出文本的高精度,团队还启动了DLC基础评论基准测试,以通过准确性级别来衡量描述的质量,而不是严格比较文本参考。 DAM-3B领导7个基准测试,包括LVIS和FLICKR30K实体,平均准确度为67.3%,超过了GPT-4O和Videorefer等模型。不仅仅是FillingDam-3B是本地描述领域的技术差距,而且了解上下文和高质量数据技术的体系结构还为没有障碍,机器人和视频内容评估的工具领域开辟了新的可能性。 【来源:这在家】
当前网址:https://www.unwindsessions.com//a/keji/762.html


