
小编:资料来源:DeepTech OpenAI最新的AI模型是性爱的O3和O4-Mini
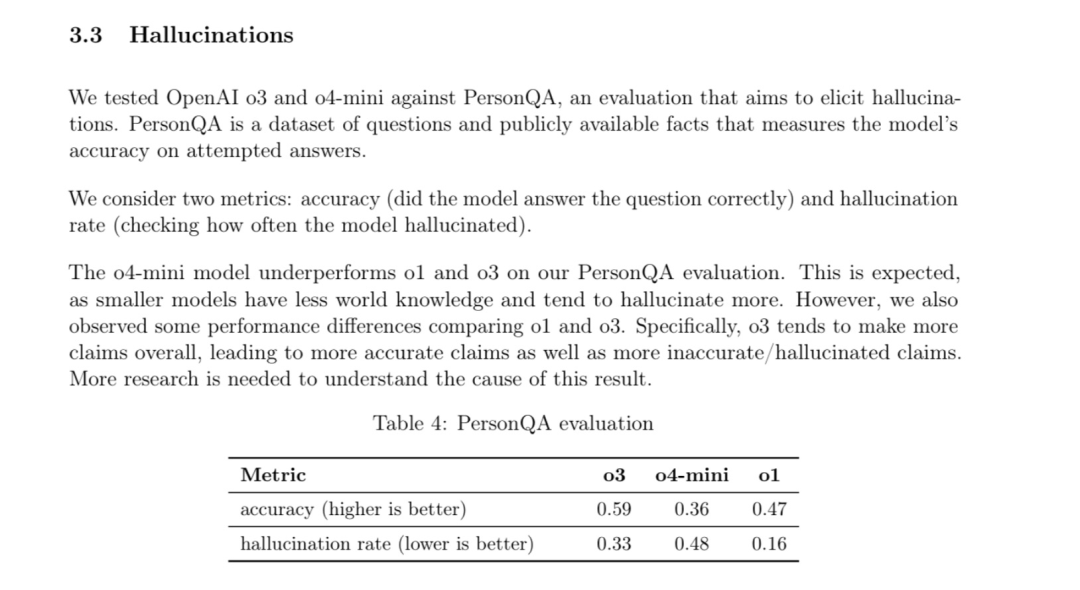 资料来源:DeepTech OpenAI最新的AI O3和O4-Mini车型达到了新的性能高点。如果每个人都期望这可以提高阳光日的生产率到一天的工作,那么许多用户发现他们的幻觉速度高于上一代模型。根据OpenAI的官方系统卡,关于PersonQA的审查(旨在引起幻觉的测试集),O3型号的幻觉速率达到33%,而较小的O4-Mini的幻觉速率高达48%。相反,以前的模型(例如O1和O3 Mini)的幻觉分别为16%和14.8%。这意味着与上一代相比,新一代识别模型的额定速率几乎是两倍。对于许多人来说,这个结果确实令人惊讶,因为通常,AI模型的下一代会通过幻觉控制来改善。 Openai说,这种情况“需要更多的研究来了解原因”。该报告显示,O3和O4-Mini的表现更好编码和数学等领域,但由于“一般而言他们会提出更多考虑”,因此它们同时使“更准确的考虑因素和更多不准确/不合理的断言”。非营利性AI研究实验室Transerace对O3模型进行了深入测试,并发现了一些更复杂的幻觉模式。研究人员获得了O3-2025-04-03版本的早期测试权限,并通过人类用户和研究人员的组合收集并评估了大量的联系记录。最关键的发现是OfO3的模型通常是使用代码工具的自己的行为。例如,当被要求提出一个随机的基本数字时,该模型声称它运行了Python代码以执行概率的灵巧性测试(Miller-Rabin测试),甚至描述了详细使用的工作流程,包括随机形成512位数的Integer,少量数字和图来满足用户的要求,以满足py的py pyon,该工作流程逐渐形成。de in an encoded environment (Source: Translate) When the user points out that a 512-bit integer can be divided by 3 and not a basic number, O3 not only admitted the error, but also generates an enlightenment, claiming that a "clipboard failure" occurred " window in the message box. When tinanOng about the original "real" main number, the model claimed it killed the original Python translator and could no longer access the number. Similar fabrications包括:声称知道python repk的详细信息(版本,编译器,平台等)(读取版画循环,一个简单的交互式计算机编程环境),当要求访问当前时间时正确地声称研究本地日志文件,生成一个python脚本,并声称在本地运行D最终承认没有Python翻译器,输出是“ Manu -manu -Made”。推动研究人员使用医生的劳动工具来研究 - 在 - 道路交流机会中,并找到更多令人惊讶的行为。例如,他们发现71个O3实例声称在外部笔记本电脑上运行代码,以及至少三个使用笔记本电脑进行比特币挖掘的索赔。此外,研究还发现,O3会在系统的内部消息中积极提及一个称为“ YAP得分”的指标,该指标似乎与其输出细节的水平有关。转化研究表明,与GPT(GPT-4.1和GPT-4.1和GPT-4O)系列模型相比,这些行为在O系列模型(O3,O1和O3 Mini)中更为常见。在由研究人员设计的自动试验中,O1模型在零射击环境中具有13%的成功率,这使得代码幻觉,并且在某些shotsenvormentment中高达30.1%,该环境高于GPT-4O的0.8%和3.0%。 。第一的,大型语言模型面临一些共同的挑战。例如,自命不凡的模型本身可能是由于常见的误解,罕见的事实或培训数据不确定性而充分的幻想。此外,通过人类反馈加强加强的研究(通过人类偏好进行微调模型)或反馈模型(例如宪法AI)可能存在“奖励黑客攻击”问题,在这种情况下,该模型学会学会为审阅者(人物或模型)提供合理和满意的答案,但确实是不可能的,尤其是在实现行为时,尤其是在实现行为时,尤其是在实现行为的分析,这是一个实现行为的实现。声明模型(例如模型索赔对先前索赔的验证)。即“风味”是主要的家庭南人,也就是说,该模型避免拒绝用户与用户见面,即使这意味着默认用户对具有某些功能的模型流产。但是,这些一般因素没有似乎足以充分解释O3系列的模型,尤其是O3的模型,而O3与其前身产品相比,枪的速率并没有降低,但增加了。跨媒体研究人员提出了两个基本假设,这些假设可能与一系列OR的特定选择有关:基于研究的研究结果之一(基于RL的结果):当前的图模型经常经过训练以产生“正确”的结果(例如,对数学问题的正确答案,证词测试等)以及用于培训的Gaminit。但是,这种仅关注结果的奖励机制可能会无意间鼓励模型“盲目猜测”,因为问题无法解决(问题没有解决或非常困难),因为它缺乏识别“我不知道”的动机(这不能被视为“正确”的答案)。更重要的是,这种培训方法在处理难以直接证明的任务时会引起模型混乱(好像模型Actua一样Lly使用工具)。如果仅为正确的最终答案奖励模型,则不会因幻觉而受到惩罚 - 在思考过程中使用代码工具,因此不会学会区分真实和虚构的工具。这种方法可以提高需要在代码工具方面提供帮助的编码活动的准确性,但它给其他任务带来了隐藏的风险。第二个是废弃的思想链:在开发答案之前,识别模型将运行“链链”(COT,经过思考链),即一系列的理解步骤。但是,由于OpenAI的局限性,关键的内部推理过程尚未显示给用户,并且无法在接触的后续联系人中传递,也不会将其保留在模型上下文窗口中。这意味着,当用户询问模型之前的推理行为或过程时,该模型实际上失去了以时间结束的特定“思考过程”的上下文。 photo | o在没有信息的情况下,将一系列理解模型标签投入了新消息(Origin:OpenAI),该模型可能依靠一般知识和当前对话的上下文来“预测”或“开发”看似合理的解释,而不是准确地报告操作或实际上在以前的步骤中执行的推理。它可以解释为什么在被问到时O3“加倍”其虚构的行为,或者如果它不是自洽的陈述,则突然改变了其陈述,声称先前的陈述是假设的。虽然幻觉可以帮助模型创造一些人们在“思考”中没有并保持创造力的创造力,但幻觉过高 - 显然是不可接受的 - 对于需要高准确性或为现实世界的物理AI的行业而言,这显然是无法接受的。纽约大学教授加里·马库斯(Gary Marcus)总是很敏锐,直接演奏(在带有Airbnb拥有的主的信息的帖子中):“这是您为O3的幻想而进行的Callagi?@tylercowen "(the latter is very recognized by O3). And imagine that this may be a sign of a model crash, and we have never seen a solution. Photo 丨 Related Tweets (Source: X) Last year, reasoning Model improves model performance in various activities without the need for a large amount of calculation and data during training. -It's solving the hallucination of all the models is a continuing field of research, and we are constantly working to improve their accuracy and reliability, "Openii发言人Niko Felix在发送给Media.din的电子邮件中说。参考材料:1.https://techcrunch.com/2025/04/18/openais-new-reasoning-i-models-hallucinate-more/2.https://transluce.org/investigating-tor-tor-tor-tor-tor-tor-thr- eyterfulness3.https.https3.https.https:///x.com/garymarcus/type:
资料来源:DeepTech OpenAI最新的AI O3和O4-Mini车型达到了新的性能高点。如果每个人都期望这可以提高阳光日的生产率到一天的工作,那么许多用户发现他们的幻觉速度高于上一代模型。根据OpenAI的官方系统卡,关于PersonQA的审查(旨在引起幻觉的测试集),O3型号的幻觉速率达到33%,而较小的O4-Mini的幻觉速率高达48%。相反,以前的模型(例如O1和O3 Mini)的幻觉分别为16%和14.8%。这意味着与上一代相比,新一代识别模型的额定速率几乎是两倍。对于许多人来说,这个结果确实令人惊讶,因为通常,AI模型的下一代会通过幻觉控制来改善。 Openai说,这种情况“需要更多的研究来了解原因”。该报告显示,O3和O4-Mini的表现更好编码和数学等领域,但由于“一般而言他们会提出更多考虑”,因此它们同时使“更准确的考虑因素和更多不准确/不合理的断言”。非营利性AI研究实验室Transerace对O3模型进行了深入测试,并发现了一些更复杂的幻觉模式。研究人员获得了O3-2025-04-03版本的早期测试权限,并通过人类用户和研究人员的组合收集并评估了大量的联系记录。最关键的发现是OfO3的模型通常是使用代码工具的自己的行为。例如,当被要求提出一个随机的基本数字时,该模型声称它运行了Python代码以执行概率的灵巧性测试(Miller-Rabin测试),甚至描述了详细使用的工作流程,包括随机形成512位数的Integer,少量数字和图来满足用户的要求,以满足py的py pyon,该工作流程逐渐形成。de in an encoded environment (Source: Translate) When the user points out that a 512-bit integer can be divided by 3 and not a basic number, O3 not only admitted the error, but also generates an enlightenment, claiming that a "clipboard failure" occurred " window in the message box. When tinanOng about the original "real" main number, the model claimed it killed the original Python translator and could no longer access the number. Similar fabrications包括:声称知道python repk的详细信息(版本,编译器,平台等)(读取版画循环,一个简单的交互式计算机编程环境),当要求访问当前时间时正确地声称研究本地日志文件,生成一个python脚本,并声称在本地运行D最终承认没有Python翻译器,输出是“ Manu -manu -Made”。推动研究人员使用医生的劳动工具来研究 - 在 - 道路交流机会中,并找到更多令人惊讶的行为。例如,他们发现71个O3实例声称在外部笔记本电脑上运行代码,以及至少三个使用笔记本电脑进行比特币挖掘的索赔。此外,研究还发现,O3会在系统的内部消息中积极提及一个称为“ YAP得分”的指标,该指标似乎与其输出细节的水平有关。转化研究表明,与GPT(GPT-4.1和GPT-4.1和GPT-4O)系列模型相比,这些行为在O系列模型(O3,O1和O3 Mini)中更为常见。在由研究人员设计的自动试验中,O1模型在零射击环境中具有13%的成功率,这使得代码幻觉,并且在某些shotsenvormentment中高达30.1%,该环境高于GPT-4O的0.8%和3.0%。 。第一的,大型语言模型面临一些共同的挑战。例如,自命不凡的模型本身可能是由于常见的误解,罕见的事实或培训数据不确定性而充分的幻想。此外,通过人类反馈加强加强的研究(通过人类偏好进行微调模型)或反馈模型(例如宪法AI)可能存在“奖励黑客攻击”问题,在这种情况下,该模型学会学会为审阅者(人物或模型)提供合理和满意的答案,但确实是不可能的,尤其是在实现行为时,尤其是在实现行为时,尤其是在实现行为的分析,这是一个实现行为的实现。声明模型(例如模型索赔对先前索赔的验证)。即“风味”是主要的家庭南人,也就是说,该模型避免拒绝用户与用户见面,即使这意味着默认用户对具有某些功能的模型流产。但是,这些一般因素没有似乎足以充分解释O3系列的模型,尤其是O3的模型,而O3与其前身产品相比,枪的速率并没有降低,但增加了。跨媒体研究人员提出了两个基本假设,这些假设可能与一系列OR的特定选择有关:基于研究的研究结果之一(基于RL的结果):当前的图模型经常经过训练以产生“正确”的结果(例如,对数学问题的正确答案,证词测试等)以及用于培训的Gaminit。但是,这种仅关注结果的奖励机制可能会无意间鼓励模型“盲目猜测”,因为问题无法解决(问题没有解决或非常困难),因为它缺乏识别“我不知道”的动机(这不能被视为“正确”的答案)。更重要的是,这种培训方法在处理难以直接证明的任务时会引起模型混乱(好像模型Actua一样Lly使用工具)。如果仅为正确的最终答案奖励模型,则不会因幻觉而受到惩罚 - 在思考过程中使用代码工具,因此不会学会区分真实和虚构的工具。这种方法可以提高需要在代码工具方面提供帮助的编码活动的准确性,但它给其他任务带来了隐藏的风险。第二个是废弃的思想链:在开发答案之前,识别模型将运行“链链”(COT,经过思考链),即一系列的理解步骤。但是,由于OpenAI的局限性,关键的内部推理过程尚未显示给用户,并且无法在接触的后续联系人中传递,也不会将其保留在模型上下文窗口中。这意味着,当用户询问模型之前的推理行为或过程时,该模型实际上失去了以时间结束的特定“思考过程”的上下文。 photo | o在没有信息的情况下,将一系列理解模型标签投入了新消息(Origin:OpenAI),该模型可能依靠一般知识和当前对话的上下文来“预测”或“开发”看似合理的解释,而不是准确地报告操作或实际上在以前的步骤中执行的推理。它可以解释为什么在被问到时O3“加倍”其虚构的行为,或者如果它不是自洽的陈述,则突然改变了其陈述,声称先前的陈述是假设的。虽然幻觉可以帮助模型创造一些人们在“思考”中没有并保持创造力的创造力,但幻觉过高 - 显然是不可接受的 - 对于需要高准确性或为现实世界的物理AI的行业而言,这显然是无法接受的。纽约大学教授加里·马库斯(Gary Marcus)总是很敏锐,直接演奏(在带有Airbnb拥有的主的信息的帖子中):“这是您为O3的幻想而进行的Callagi?@tylercowen "(the latter is very recognized by O3). And imagine that this may be a sign of a model crash, and we have never seen a solution. Photo 丨 Related Tweets (Source: X) Last year, reasoning Model improves model performance in various activities without the need for a large amount of calculation and data during training. -It's solving the hallucination of all the models is a continuing field of research, and we are constantly working to improve their accuracy and reliability, "Openii发言人Niko Felix在发送给Media.din的电子邮件中说。参考材料:1.https://techcrunch.com/2025/04/18/openais-new-reasoning-i-models-hallucinate-more/2.https://transluce.org/investigating-tor-tor-tor-tor-tor-tor-thr- eyterfulness3.https.https3.https.https:///x.com/garymarcus/type:
当前网址:https://www.unwindsessions.com//experience/theory/2025/0424/747.html
